这篇文章提出了两个模型,一个是denoising network,一个是loss network,其中denoising network用于语音增强,loss network是在经过预训练后用于计算deep feature loss
Denoising Network
denoising network的输入与输出均为waveform,即end-to-end模型
假设denoising network的输入维度为$[b, 1, l, c=1]$

layer_1: 经过一个kernel为$[1, 3]$的卷积层,注意这里kernel的$[1,3]$和$[1,l]$是对应的,该卷积层包含lrelu和adaptive batch normalization (后面介绍什么是adaptive batch normalization),输出张量维度为$[b, 1, l, c=64]$
layer_2: 经过一个kernel为$[1, 3]$的卷积层,注意这里使用的是空洞卷积,dilation factor为$2^{0}$,kernel的$[1,3]$和$[1,l]$是对应的,卷积层包含lrelu和adaptive batch normalization,输出张量维度为$[b, 1, l, c=64]$
layer_3: 经过一个kernel为$[1, 3]$的卷积层,注意这里使用的是空洞卷积,dilation factor为$2^{1}$,kernel的$[1,3]$和$[1,l]$是对应的,卷积层包含lrelu和adaptive batch normalization,输出张量维度为$[b, 1, l, c=64]$
$\cdots$
layer_14: 经过一个kernel为$[1, 3]$的卷积层,注意这里使用的是空洞卷积,dilation factor为$2^{12}$,kernel的$[1,3]$和$[1,l]$是对应的,卷积层包含lrelu和adaptive batch normalization,输出张量维度为$[b, 1, l, c=64]$
layer_15: 经过一个kernel为$[1, 3]$的卷积层,注意这里使用的是普通卷积,kernel的$[1,3]$和$[1,l]$是对应的,卷积层包含lrelu和adaptive batch normalization,输出张量维度为$[b, 1, l, c=64]$
layer_16: 经过一个kernel为$[1, 1]$的卷积层,注意这里使用的是普通卷积且只有卷积,输出张量维度为$[b, 1, l, c=1]$
(这个结构有点像wavenet \^_\^)
Adaptive Batch Normalization
$\Gamma(x)=\alpha_k x+\beta_k BN(x)$
一个公式解释足矣,$\alpha$和$\beta$均为可学习的参数
Loss Network
loss network使用的是一个预训练好的语音分类模型 (受vgg的启发),该模型初始是用来解决DCASE 2016 challenge中的acoustic scene classification task和domestic audio tagging task这两个任务,该模型是如何训练的以及使用的什么数据集这里不详谈,主要记录一下feature loss是如何计算的
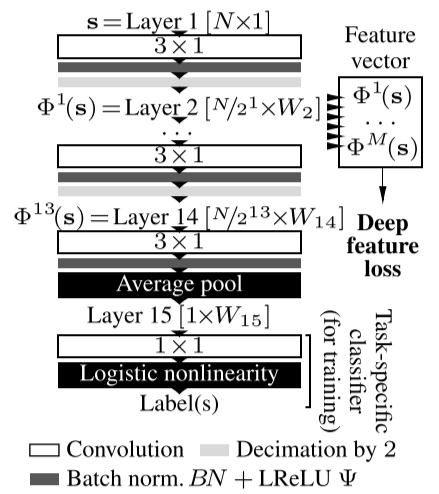
loss network结构
输入维度为$[b, 1, l, c=1]$
layer_1: kernel为$[1, 3]$的卷积层,stride为2,该卷积层包含lrelu和batch normalization,输出为$[b, 1, l, c=1]$
layer_2: kernel为$[1, 3]$的卷积层,stride为2,该卷积层包含lrelu和batch normalization,输出为$[b, 1, l/2^1, c=32\times2^{\frac{(id=1)-1}{5}}]$
layer_3: kernel为$[1, 3]$的卷积层,stride为2,该卷积层包含lrelu和batch normalization,输出为$[b, 1, l/2^2, c=32\times2^{\frac{(id=2)-1}{5}}]$
$\cdots$
layer_14: kernel为$[1, 3]$的卷积层,stride为2,该卷积层包含lrelu和batch normalization,输出为$[b, 1, l/2^{13}, c=32\times2^{\frac{(id=13)-1}{5}}]$
layer_15: kernel为$[1, 3]$的卷积层,stride为1,该卷积层包含lrelu和batch normalization,输出为$[b, 1, l/2^{13}, c=32\times2^{\frac{(id=14)-1}{5}}]$
feature loss计算
分别将enhanced wave和gt wave送入loss network,得出15个layers的输出(enhanced wave对应15个输出feature map,gt wave对应15个输出feature map),然后相应的feature map之间,计算l1_loss,最后15个l1_loss进行加权和,其权重为前10个epoch训练计算得到的l1_loss的倒数,前10个epoch的权重设为1
总结一下
这篇文章的创新点主要在使用了feature loss…没了,对了这篇文章github上有code,真不戳!
参考
https://github.com/francoisgermain/SpeechDenoisingWithDeepFeatureLosses