总览
单通道的语音降噪有两种方式:
- 直接在一维的时域原始波形上进行操作
- 把一维的时域波形转换为二维的时频谱再进行操作
第二种方式的主流方法是预测一个时频掩膜用来降噪,PHASEN也是采用这种方法。
总的来说,PHASEN是在时频谱(复数域)基础上预测了一个幅度掩膜$M$和一个相位掩膜$\psi$,然后用输入的时频谱的模(实数域)乘上两个掩膜得到低噪声时频谱,公式如下:
\[S^{out}=abs(S_{in}) \circ M \circ \psi\]PHASEN的结构

首先整个模型呈双流结构,强度流用来预测幅度掩膜$M$,相位流用来预测相位掩膜$\psi$。也可以把模型分为三个部分:TSB之前、TSBs、TSB之后。
我个人在理解一个神经网络模型的时候,比较喜欢从模型的输入输出维度入手,所以下面会着重分析模型各部分的维度变化。
模型的输入是复数域上二维的时频谱,所以要先对一维的时域波形进行STFT(短时傅里叶变换)。其次神经网络用到批处理,所以输入$S_{in}$的维度应当是[B,2,t_len,f_len],这里的第二个维度2是指时频谱的实部和虚部。
TSB之前:
TSB之前的强度流是两个二维卷积层,卷积核分别为$1 \times 7$(1对应时域)和$7 \times 1$(7对应时域)。这两个卷积层不改变输入tensor的时域和频域长度,只改变第二个维度的通道数,也就是说这两个卷积层的输出维度都是[B,c_a,t_len,f_len],至于c_a是多少,论文中没有提(毕竟没有开源),参考文末一位大佬复现的模型代码,可以将c_a设置为24。
TSB之前的相位流也是两个二维卷积层,卷积核分别为$5 \times 3$(5对应时域)和$25 \times 1$(25对应时域)。同强度流一样,这两个卷积层也不改变输入tensor的时域和频域长度,只改变第二个维度的通道数,这两个卷积层的输出维度都是[B,c_p,t_len,f_len],根据参考可以将c_p设置为12。
TSBs:

这一部分由三个TSB模块级联而成。
每个TSB内部的强度流由两个FTB和三个二维卷积层构成。FTB以及三个卷积层的输入和输出维度都是[B,c_a,t_len,f_len]。
TSB内部的相位流比较简单,由两个卷积层构成,其输入输出维度都是[B,c_p,t_len,f_len],但需要注意的一点是,相位流的每个卷积层之前需要进行layer normalization。
TSB的最末尾,双流需要交换信息,公式如下:
\[S^{A_{i+1}}=f_{P2A}(S^{A_i}_4,S^{P_i}_2)\] \[S^{P_{i+1}}=f_{A2P}(S^{P_i}_2,S^{A_i}_4)\] \[f_i(x_1,x_2)=x_1 \circ Tanh(conv(x_2))\]由于$S^{A}$和$S^{P}$的第二维度(通道数)不相同,所以信息交换也要包含通道数的变换,这里可以起到通道数变换的有两个地方,一是圆圈代表的element-wise multiplication(在两个维度不相同的张量element-wise multiplication时,会以某种方式复制其中一个张量至与另一个张量维度相同再相乘),二是一个$1 \times 1$的卷积层。我更倾向于使用卷积层来做通道变换。也就是:
$S^{A_i}$的维度:[B,c_a,t_len,f_len]
$conv(S^{A_i})$的维度:[B,c_p,t_len,f_len]
$S^{P_i} \circ Tanh(conv(S^{A_i}))$的维度:[B,c_p,t_len,f_len]
$S^{P_i}$的维度:[B,c_p,t_len,f_len]
$conv(S^{P_i})$的维度:[B,c_a,t_len,f_len]
$S^{A_i} \circ Tanh(conv(S^{P_i}))$的维度:[B,c_a,t_len,f_len]
TSB中的FTB
这篇论文提出了两个创造性的点:
- 双流模型的双流之间需要相互交换信息,目的是为了更好的预测相位掩膜。
- FTB模块( frequency transformation blocks ),目的是为了捕获频域上的全局相关性。
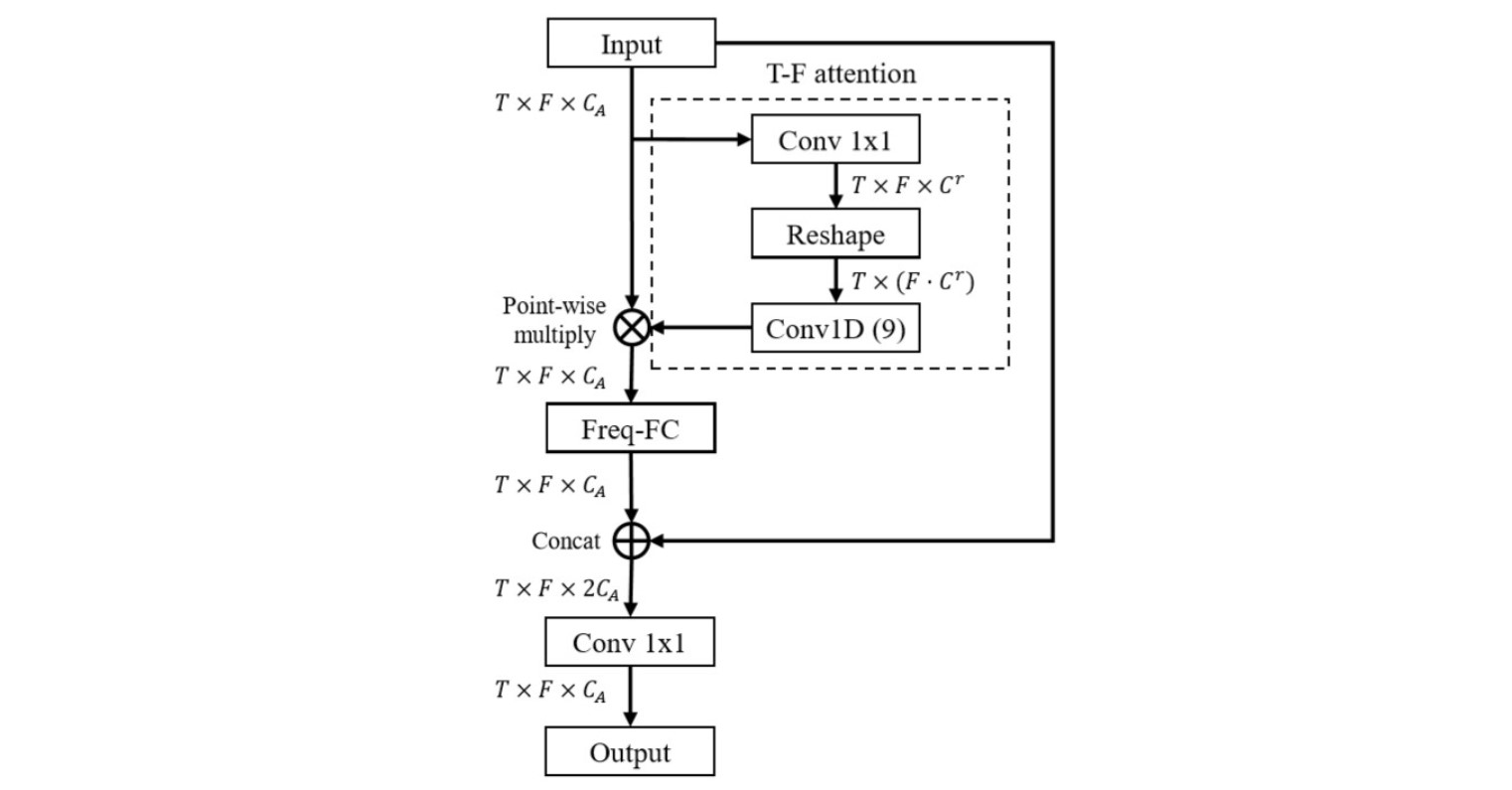
下面来分析FTB模块,其输入输出维度都是:[B,c_a,t_len,f_len]。
首先要关注的是T-F attention,这里用到了注意力机制,所以维度变换略微复杂。
T-F attention 一开始先用一个$1 \times 1$的卷积层将输入张量的通道数从c_a降至c_r,此处c_r为5,即输出维度为[B,c_r,t_len,f_len],然后进行reshape,结果维度为[B,c_r*f_len,t_len]。接下来是关键一步,一个卷积核为9的一维卷积,输出维度为[B,c_a,t_len],这个输出要和FTB最开始的输入做一次element-wise multiplication,由于维度不匹配,所以会将[B,c_a,t_len]的张量复制f_len次再与[B,c_a,t_len,f_len]的张量相乘。
Element-wise multiplication后的张量维度为[B,c_a,t_len,f_len],这个张量要通过一个不要偏置的全连接层,其权重被论文称为frequency transformation matrix (FTM),权重的维度为[f_len,f_len],这一步是FTB的核心,输出的维度是[B,c_a,t_len,f_len]。
全连接的输出又要和FTB最开始的输入进行合并,即将两个[B,c_a,t_len,f_len]张量合并为一个[B,2*c_a,t_len,f_len]的张量,最后通过一个$1 \times 1$的卷积层降低通道数得到维度为
[B,c_a,t_len,f_len]的输出。
TSBs之后
TSBs之后的强度流首先通过一个$1 \times 1$的卷积层将[B,c_a,t_len,f_len]降低至[B,c_r,t_len,f_len],此处c_r等于8。其输出结果要进入一个BiLSTM,BiLSTM需要设置参数 hidden_size,这里盲猜为300,其输出维度为[B,t_len,hidden_size*2]。事实上,张量在进入BiLSTM之前,要进行一次reshape,因为BiLSTM对输入张量的shape是有要求的,所以[B,c_r,t_len,f_len]要先reshape为[B,t_len,c_r*f_len],而后通过BiLSTM得到[B,t_len,hidden_size*2]。之后通过两个600的FC层得到输出[B,t_len,600],最后通过一个257的FC层得到$M$,维度为[B,t_len,257]
这里要说明一下,因为论文中有说明在STFT时的FFT长度为512,那么时频谱的维度就应该是[t_len,512/2+1],即f_len=257,而$M$应当具有和时频谱相同的维度,那为什么论文原图中最后的FC层的输出是514通道呢?我只能说可能论文写错了吧……
TSBs之后的相位流经过一个$1 \times 1$的卷积层将[B,c_p,t_len,f_len]降低至[B,2,t_len,f_len]然后进行一下幅度正则化即可。输出$\psi$的维度即为[B,2,t_len,f_len],第二维的2表示复数的实部和虚部。
至此,模型的前向传播过程就分析完了,得到了幅度掩膜$M$和相位掩膜$\psi$,然后便可用公式$S^{out}=abs(S^{in})\circ M \circ \psi$得到估计的时频谱$S^{out}$
Loss的计算
公式如下:
\[L=0.5L_a+0.5L_p\] \[L_a=MSE(abs(S^{out}_{cprs}),abs(S^{gt}_{cprs}))\] \[L_p=MSE(S^{out}_{cprs},S^{gt}_{cprs})\]$S^{gt}$就是指无噪声的时频谱,$S_{cprs}$是指幂律压缩时频谱(power-law compressed spectrogram),幂律压缩参数为0.3,坦白讲我一个菜鸡并不知道什么是幂律压缩,参考了其他大佬的复现代码之后才知道。这里有个问题,无论是$S^{gt}$还是$S^{out}$,它们都是复数,而幂律压缩是对实数的操作,所以应当先abs()运算,再压缩,即$abs(S^{gt})_{cprs}$,但这样的话$L_p$和$L_a$应该怎么区分呢?参考了大佬的复现后,我这样做:
\[L_{a}=MSE(abs(S^{out})_{cprs},abs(S^{gt})_{cprs})\] \[L_{p}=MSE(S^{out}\circ \frac{abs(S^{out})_{cprs}}{abs(S^{out})},S^{gt}\circ \frac{abs(S^{gt})_{cprs}}{abs(S^{gt})})\]关于数据集
论文中主要使用了两个数据集:AVSpeech+AudioSet和Voice Bank+DEMAND
AVSpeech+AudioSet这个数据集…它是从YouTube上扒下来的视频的语音构成的数据集,这个数据集我只找到了一个csv文档记录着所有视频在YouTube上的ID和截取的时间片段的始终,写个脚本去扒YouTube也不是不行,但是在国内吧,这个网……emmmmmmmm
Voice Bank+DEMAND是一个开源数据集,并不是很大,非常友好,我也是使用这个数据集复现的,效果还不错,这里贴个地址https://datashare.is.ed.ac.uk/handle/10283/2791
这是voicebankhttps://datashare.is.ed.ac.uk/handle/10283/3443
这是DEMAND数据集https://zenodo.org/record/1227121#.Xppqs_j7RrR
我所参考的一个仓库的contributor使用的好像是一个普通话数据集,比较大,15G左右,鉴于网速慢我并没有采用,这里也贴上地址https://www.openslr.org/33/
关于如何使用Voice Bank+DEMAND数据集
AVSpeech+AudioSet数据集中的语音最短的也不低于3s,所以对于这个数据集,论文使用的方法是切割为3s等长的片段进行训练,具体的使用方法并没有详细说明。Voice Bank+DEMAND数据集中的语音最短的不低于1s,一开始我也是按照3s切割的,对于短于3s的数据我采用补0的方式补齐为3s,但这种补0的方式会引入大量无效数据,导致最后的训练结果不理想。后来脑子反应过来了,将其统统切割1s的片段使用,并且如果是1.5s的语音,我会切割为两个有0.5s交叠的1s片段,这样就充分利用了数据集。
另外,在训练时数据采用的是什么长度最好在测试时也采用什么长度,一开始我在训练时采用了1s的语音片段,测试计算指标时,我是没有切割测试集,而直接送入模型去跑的(也就是送入模型的数据长度是什么长度的都有)。这样得到的测试结果指标是比较差的。后来又试了一下将测试集也切割为1s的长度,经过模型处理后再拼接为原长并和真值语音进行对比计算评估指标,这样操作的结果要好得多。
评价指标
原论文中用到了5个评价指标,分别是SDR、PESQ、CSIG、CBAK、COVL、SSNR
在伊妹儿了原作者后,得到了一个关于语音处理评价指标的计算包(matlab实现的),该包中的计算方法应该是在SPEECH ENHANCEMENT Theory and Practice一书中提到的
该包可从该地址下载https://www.crcpress.com/downloads/K14513/ K14513_CD_Files.zip
语音增强的SEGAN等绝大多数模型都是用该包进行计算的
这里简单介绍一下指标(推荐使用上面的matlab包计算指标,不推荐后文提到的方法):
-
SDR(Signal to distortion ratio):信噪比,只要学过通信或信号相关课程的人应该对这个不陌生,论文中提到了使用 mir_eval 库来计算SDR,这里贴上库的文档地址:http://craffel.github.io/mir_eval/ 以及github地址:https://github.com/craffel/mir_eval
-
SSNR(Segmental signal noise ratio):片段信噪比,借助理解短时傅里叶变换的思想,其实就是给信号分帧,对每一帧求SDR,帧与帧之间有交叠,最后取平均(希望我没理解错)
python下的ssnr代码https://www.cnblogs.com/LXP-Never/p/11071911.html#%E5%88%86%E6%AE%B5%E4%BF%A1%E5%99%AA%E6%AF%94segsnr,matlab下的ssnr代码:https://jp.mathworks.com/matlabcentral/fileexchange/33198-segmental-snr
-
PESQ(Perceptual evaluation of speech quality):语音质量评估指标,客观 Mean opinion score (MOS)的一种。关于PESQ的计算,目前我在github上找到的两个python版本的代码都不能用,网上找到了C版本的,后面有详细介绍。
-
CSIG、CBAK、COVL:这三种都是在不同的角度使用MOS去评价语音质量,详细的可以看论文: https://www.researchgate.net/publication/3457982_Evaluation_of_Objective_Quality_Measures_for_Speech_Enhancement
PESQ的计算
-
首先你的windows电脑需要gcc,下载地址:https://sourceforge.net/projects/mingw/
下载并安装完成MinGW之后,打开它,选择安装gcc-g++
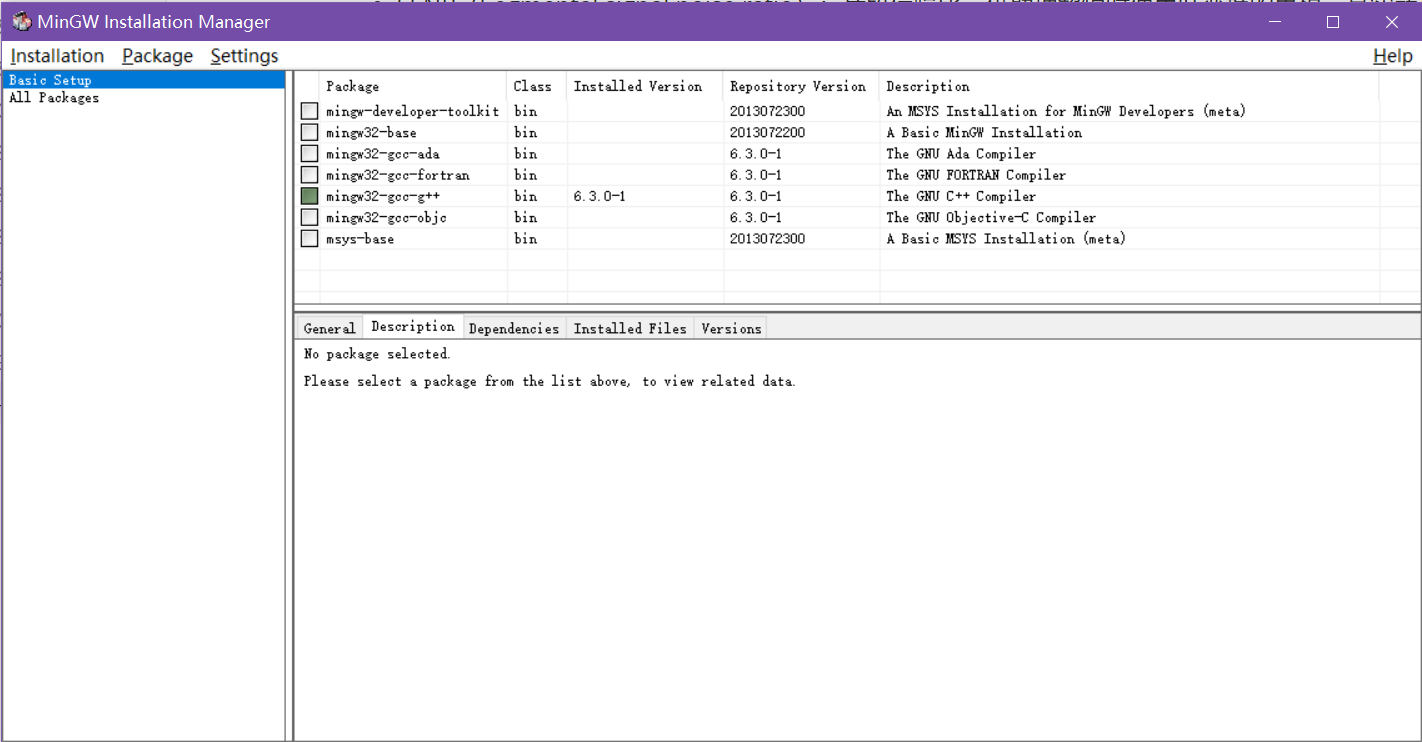
安装好之后在系统环境变量里添加
C:\MinGW\bin,gcc就弄好啦 -
下载PESQ:https://www.itu.int/rec/T-REC-P.862/en
然后
cd Software\source gcc -o PESQ *.c结果会得到一个pesq.exe,在pesq.exe的目录下使用
pesq.exe +16000 target.wav masked.wav然后就会得到两个音频文件的PESQ值(16000是采样率,好像也可以用8000)
传统的单通道语音增强算法
如何计算先验信噪比和后验信噪比?
参考博文:https://blog.csdn.net/u010592995/article/details/101782648
// Compute prior and post SNR based on quantile noise estimation.
// Compute DD estimate of prior SNR.
// Inputs:
// * |magn| is the signal magnitude spectrum estimate.
// * |noise| is the magnitude noise spectrum estimate.
// Outputs:
// * |snrLocPrior| is the computed prior SNR.
// * |snrLocPost| is the computed post SNR.
static void ComputeSnr(const NoiseSuppressionC *self,
const float *magn,
const float *noise,
float *snrLocPrior, float *logSnrLocPrior,
float *snrLocPost) {
size_t i;
for (i = 0; i < self->magnLen; i++) {
// Previous post SNR.
// Previous estimate: based on previous frame with gain filter.
float previousEstimateStsa = self->magnPrevAnalyze[i] /
(self->noisePrev[i] + 0.0001f) * self->smooth[i];
// Post SNR.
snrLocPost[i] = 0.f;
if (magn[i] > noise[i]) {
snrLocPost[i] = magn[i] / (noise[i] + 0.0001f) - 1.f;
}
// DD estimate is sum of two terms: current estimate and previous estimate.
// Directed decision update of snrPrior.
snrLocPrior[i] = 2.f * (
DD_PR_SNR * previousEstimateStsa + (1.f - DD_PR_SNR) * snrLocPost[i]);
logSnrLocPrior[i] = logf(snrLocPrior[i] + 1.0f);
} // End of loop over frequencies.
}
参考:https://github.com/huyanxin/phasen